Handling burst scaling
In this post, I will cover the improvements I made to the inference system described in the last post. The previous system supported inference over user GPUs, but those didn’t necessarily had a robust internet connection or fast SSDs, causing them to take hours to load about 50GB worth of models and environment.
The simple solution to this was to use a slightly expensive on-demand GPU service to handle the burst scaling and then offload the GPU requirements to the slower/cheaper service as the load is sustained. Although a straightforward task, it required a significant change in the codebase (including the tests) and to accomplish this we needed three things
- Load estimation
- Fast boot up (< 5mins)
- Decent scaling logic
For estimating the load, we needed to estimate how much time a particular workflow will take to complete. Though it is hard to get an exact value before running the workflow, Austin Mroz suggested an amazing idea, we can basically count the pixels the sampler is processing for the entire process and map it to the total time taken, this gave us an approximate correlation between the “load” and the time it will take to complete. Using this approximation, we can instantly estimate load for different workflows without any actual processing.
Now for booting up fast containers, loading stuff from either Docker repository or the various model providers was not an option as there was a limit on the download speed. Since I was using Runpod as the provider, they had a feature of attaching network storage to the pods, and these provided super fast transfer speeds. So for the fast containers, I loaded the network storage with all files (including the models) along with an embedded environment, that can be simply copied inside the container and run instantly. Doing this allowed us to start these containers in around 3 mins.
The scaling logic was fairly simple. I monitored the task pool at a frequency of 5 mins, and noted the total load of different task queues. Note here that the total load = no. of tasks * pixelsteps. Once I saw a change of more than 10% (either increased load or decreased load), I started the fast running containers for that particular queue. Once enough time has elasped, so that we can safely assume the load to be a “sustained” load, I started the slow/cheap containers corresponding to the fast ones. Whenever the slow containers were up and running, the corresponding fast containers would close.
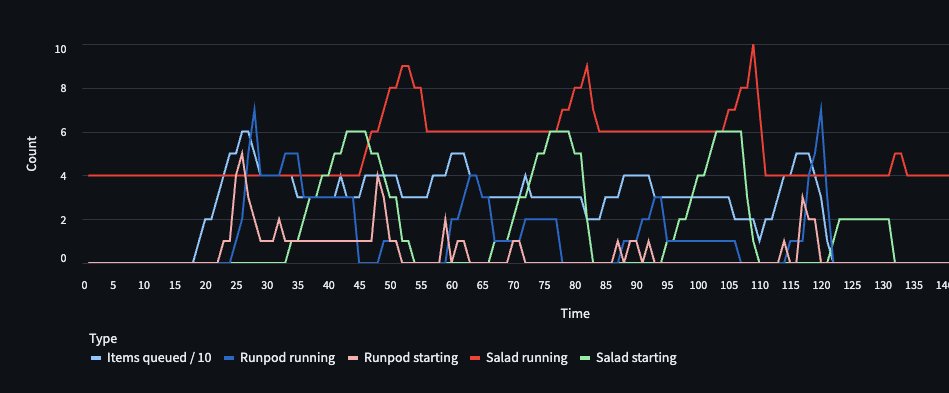
Among other things (major code restructuring, rate limiting addition, bug fixes and other feature additions) one major change that I made in the system was to replace SQS queues with Redis lists (with atomic transaction capability). Since the system was designed to only queue the number of items equal to the number of free machines, we would not have crossed a queue size of 20 for individual queues. Replacing the queues with lists had two benefits. First, we can monitor it in realtime, unlike sqs where there is a 2 min buffer window and second, we can create task queues instantly by simple code change (we don’t need to create a new infra element each time). It also cut down our costs significantly.