Inference over distributed GPUs
In this post, I will cover a system I built recently to do inference over GPU clusters, specifically the Salad GPU service. To be clear, this post is not about using multiple GPUs to perform a single inference but rather an event driven queuing system.
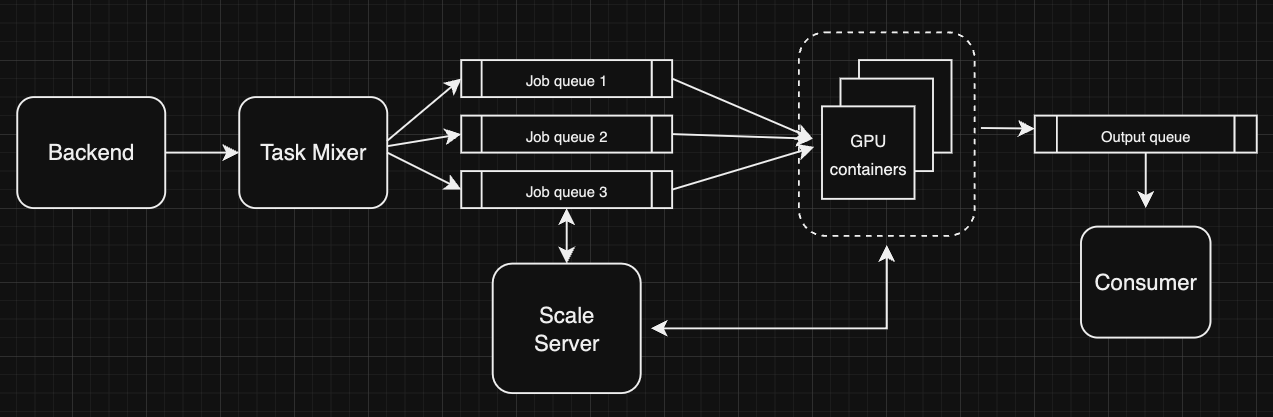
The obvious challenge was that this GPU cluster runs on consumer hardware, people connect their GPUs to Salad and Salad runs the tasks on them. Though this sounds convenient, two drawbacks of this is that firstly the GPUs can go offline anytime (even mid-process) and secondly the internet speeds can vary significantly. First, for queuing and maintaining the inference states I used the CQRS pattern (Command and Query Responsibility Segregation) and the system defined as below
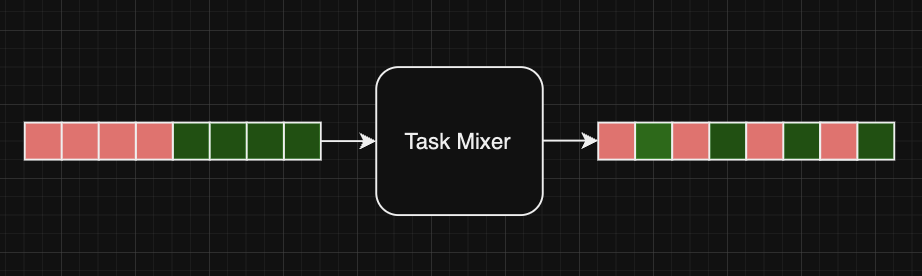
All the events go in the task mixer and at regular intervals, a homogenised mixture of tasks is pushed in the queue such that no user blocks the processing pipeline. This component also has the ability to set different priority for different users, thus prioritizing the tasks from a particular user over the others. This functionality was suggested by Peter.
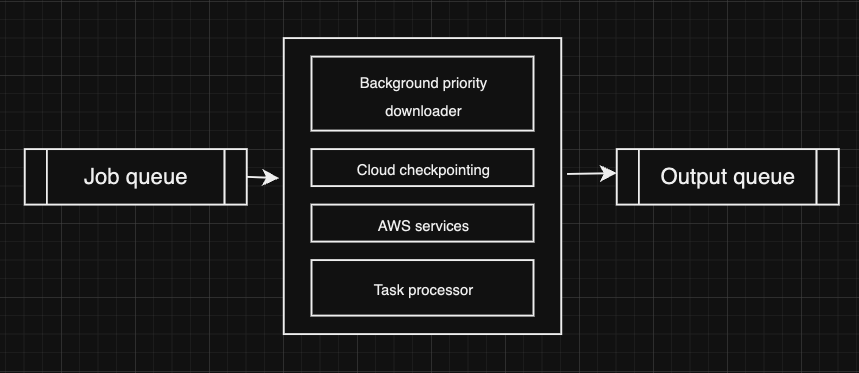
In our testing we didn’t find the gateway very robust so we flipped the process and made the containers pick the tasks directly from queue. All the outputs/errors are then pushed to the output queue which are picked by the consumer, stored in the db and then processed. For storing the results of each sampling process a modified version of AustinMroz’s checkpointing script was used, so that in the case of disconnection, the new generation will begin from where it left off. One major benefit of this system design is that the third party GPU provider can very easily be switched to something else (including having multiple providers of different kind as well). The containers also have a background download script that parallely downloads multiple files (in chunks) in the background (of files not present in the container) and has the ability to download stuff on priority as and when needed.
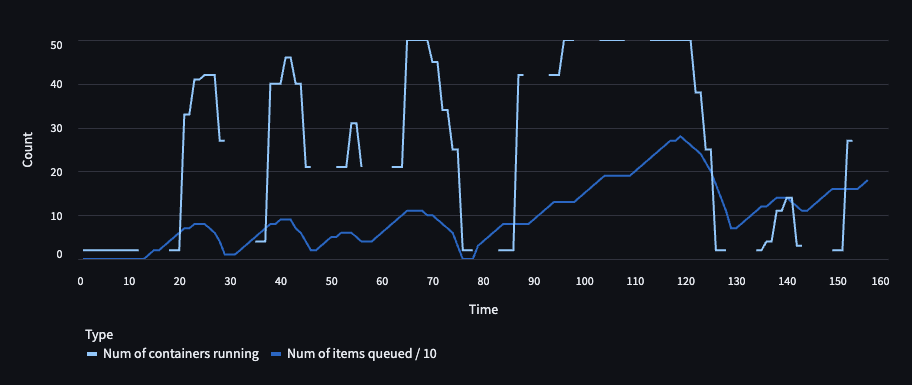
All the containers are connected to the scale server, that serves two purposes. Firstly, it scales the number of containers up or down depending upon the load. This scaling involves measuring task load, container capacity, hysteresis period and couple of other parameters. The other important function of this server is to keep a record of all the containers and their active tasks, incase of any disconnections the task is requeued. There is also a check that runs at regular intervals that takes care of many edge cases that could happen. Below is a graph of chaos testing of the system, with the breaks in the graph showing downtime of the scale server.