Deploying a Streamlit app on production
I have been working on an open source AI video generator for quite some time now. Though it’s a simple tool, it being built in Streamlit posed some challenges both in it’s internal structuring and deployment. Here, I will share some of the problems faced by me and how I solved them.
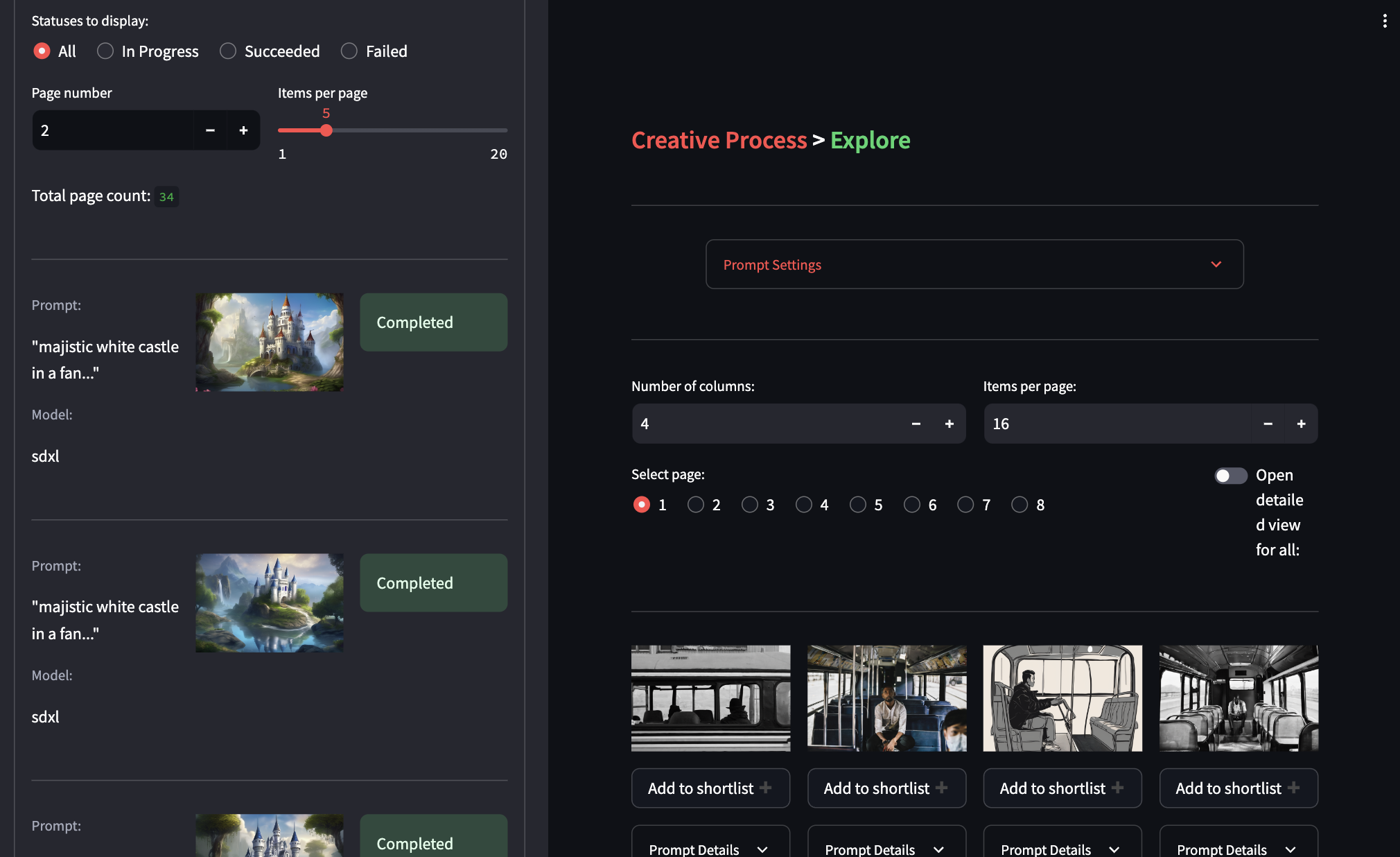
The very first thing I did to make the app scalable was to deploy it on an ECS cluster, which depending on the load will auto-scale the number of containers running. The problem with this approach is that AWS load balancer auto routes the incoming requests to containers with low load whenever the number of containers changes. Since Streamlit is server side rendered and it maintains the state locally (on the server), this switch will kill the app functioning, especially in our case since we are keeping a large amount of data in the Streamlit session state for quick reloads. After some searching I found that AWS provides the option to enable sticky sessions in ecs target group alb which maintains the user’s connection to a specific ECS container (connection is identified by browser cookies). This setting can be enabled by adding the following terraform code inside aws_alb_target_group.
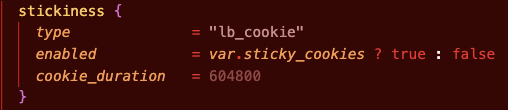
After this the problem that we encountered a lot with the app was speed. Since, Streamlit is somewhat like Flutter in the regards that it refreshes the entire app on every little change, our app was getting very slow, since we were making quite a few API calls to the backend. The solution to this required changing the deployment options and the internal app structure. In the case of deployment I noticed that the DNS resolution and the TLS handshake were taking a significant amount of time. Since the user will never see any of the https calls (Streamlit directly sends the rendered page to the end user) I can just use http instead of https. Also instead of going over the internet and doing DNS resolution, I created an internal private DNS which the Streamlit app can use to quickly connect to the backend. This more than doubled the API interaction speed.
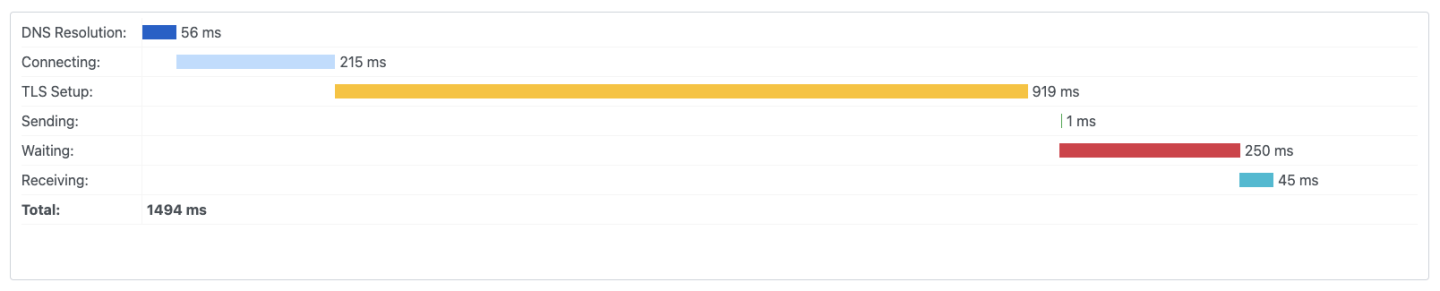
Now on the app side I tried to cache as many data models as I could. We built a simple wrapper on top of our API repository, which cached the API results in the session state. The caching logic we used was very simple, we stored the API data as they came and whenever a particular model was altered (updated/deleted) we refreshed all the related entities. This again gave us a significant speed boost. We are still looking for ways to make it even faster, but not having a proper state management solution in Streamlit creates some challenges.