Generative AI: A semi-technical look
I have been quite busy since my last post. In this post, I will cover my experience with generative AI and what I think about it from a technical perspective being a software developer. I worked on multiple personal projects, some complete, some incomplete, and some still in progress. I will start with the LLMs as it was ChatGPT that took the internet by storm. Though AI was here long ago, it was the first time that people could use it naturally with the chat interface. Having opened their API to the public everyone started building wrappers on top of it. To me as well it looked like the right opportunity to ride the AI wave or at least make something worthwhile. So, I started with the problem most software engineers are troubled by, coding. I wanted to make a program that will automatically write the code based on your existing code base and development practices. This is a high-level overview of what I thought would work.
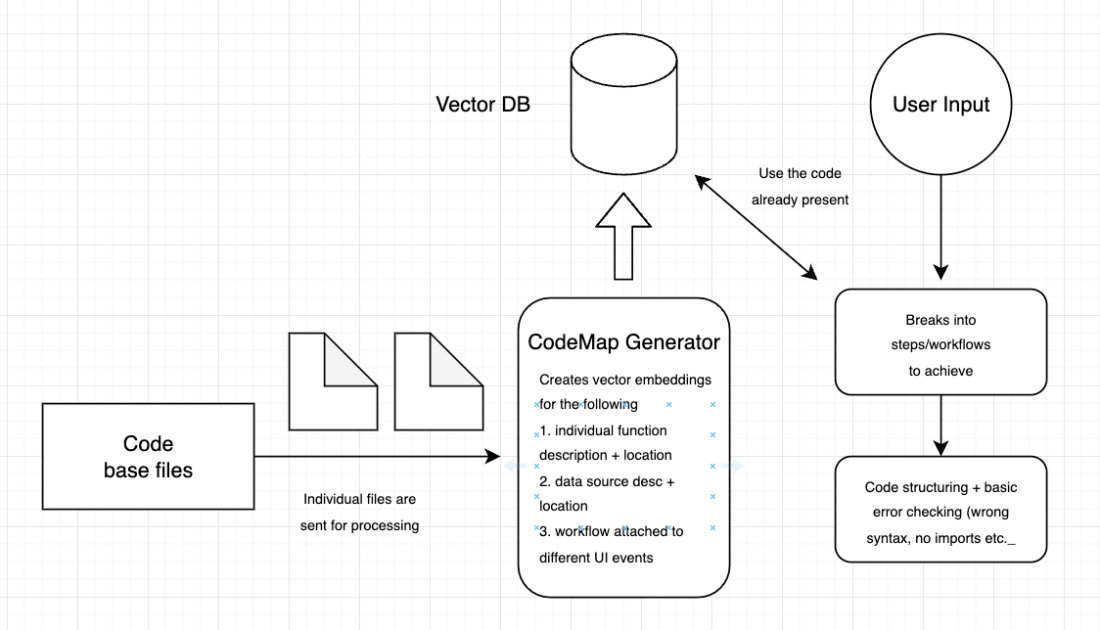
And this was the result
The results were not that great. Although ChatGPT was good at giving small code snippets, writing the entire code seemed very far fetched (I believe it still is). The chaining of multiple commands utilizing CoT and ReAct added more to the problem as a single deviation/error at one of the steps compounded heavily till the program reached the end. I tried to minimize the error in multiple ways but had no luck so I gave up. I looked at other impressive demos on Twitter but none had a good working product and everyone had the same issue. I believe even with GPT-5 coding the entire codebase is an extremely far fetched scenario. Maybe this was the major breakthrough that we would see even in the next 5-7 years.
From LLMs I switched my focus to image generation as it impressed me much more than the LLMs. I tried the base SD in the very beginning and it was super bad but when I tried Midjourney I was just blown away. I have been an admirer of art (especially fantasy art) for a long time, and seeing a computer generate such amazing images in just seconds was a surreal experience. I tried a bunch of custom models and quickly created a website where people can generate images. I also tried a bunch of other things to see what sticks, but the pace of development in AI space was so fast, with players picking millions in funding that it was almost impossible to keep up. A simple example would be Prompthunt and similar sites, which started by selling prompts but their business model was soon invalidated when both Stable Diffusion and Midjourney launched their prompt predictor tool (Clip and /describe). Here’s the site that I made, I am still experimenting with different things on this and hoping I find the right hook to monetize this somehow.
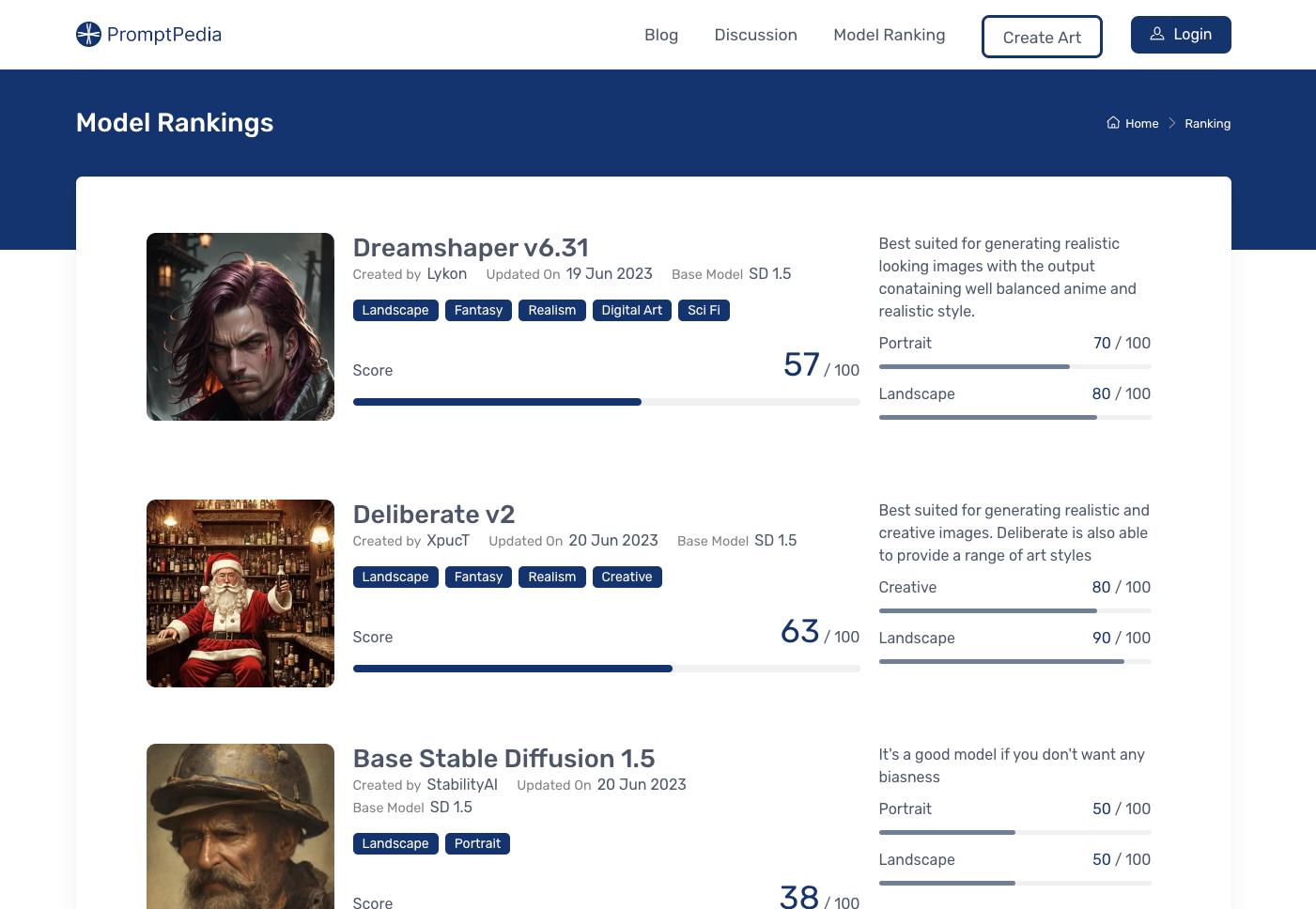
Custom models generated amazing results while Midjourney is in a league of its own. Midjourney reaching $1 billion ARR shows just how much of a big deal this was. But one major issue I felt with image generation was the loss of control and I think text-to-image is not the right way to go about it. A different way to think about this is the data filling, we provide some text which is a couple of KBs, and the AI model generates an image that is a couple of MBs. This thousandfold data creation is largely driven by the model’s training and there is very little control we have over it. For example, I wanted to make an image of a fantasy land in a dark setting with rocks flying. I already had its image by some artist but wanted to make it even better. No matter what I did it was almost impossible to get what I want, the only solution that could work in these scenarios is to draw the image from scratch by hand. AI image models are still a black box and though you can still achieve a lot by proper prompt engineering and other control techniques (like controlnet, image-to-image, and parameter tuning) it’s nowhere close to artists creating art from scratch.
I next started experimenting with AI video generation. At the time there were just some basic demos out there by Runway but nothing concrete. A lot of people on Reddit and Twitter were generating videos by converting every single frame than removing the noise artifacts. But in my opinion, these simple restyling can be better done by static programs like EBsynth. I tried a lot of different things, the main ones being multi controlnet and image-to-image at different settings but couldn’t get a good result. The only way that seemed to work was to train an SD model on both character and style of the particular character that you wish to transform and then apply multi-controlnet along with the custom model that you created. Of course, this makes very little practical sense and thus still I have no good way to make this work. Check one of the results that I generated below.
I believe there is still significant research and development left in the AI space. Though the results are impressive and can perform very well on small tasks they are still far from practical use cases and nowhere near what the AI doomsayer would have us believe. I will keep experimenting with this stuff and update it here. The quote from Yann LeCun, Chief AI scientist at Meta summarizes this perfectly.